Introduction
Eigendecomposition of a matrix, in which we decompose the matrix into a set of eigenvectors and eigenvalues, shows us to the information about the universal and functional properties of the matrix. Such properties might not be obvious from the representation of the matrix as an array of elements. This blog introduces the related concepts of matrix eigendecomposition and methods to compute eigenvectors and eigenvalues of a matrix.
Eigenvalue and Eigenvector
An eigenvector of a square matrix is a nonzero vector such that multiplication by alters only the scale of : . Where is the eigenvalue corresponding to the eigenvector .
Note that if is the eigenvector of , then is also the eigenvector of with the same eigenvalue . Therefore, we usually focus on the unit eigenvectors, which means . Even that is not quite enough to make the eigenvector unique, since we may still multiply it by to obtain another eigenvector with the same eigenvalue. Hence, we shall also require that the first nonzero component of an eigenvector be positive.
Intuitively, the multiplication maps the vector into another space, probably changing its size, direction or dimension. Particularly, if is the eigenvector of , only scale by corresponding eigenvalue . shows the differences between the transformations of eigenvectors and non-eigenvectors. For eigenvectors and of , the multiplication only changes their size. For non-eigenvectors , the multiplication not only changes its size but also its direction.
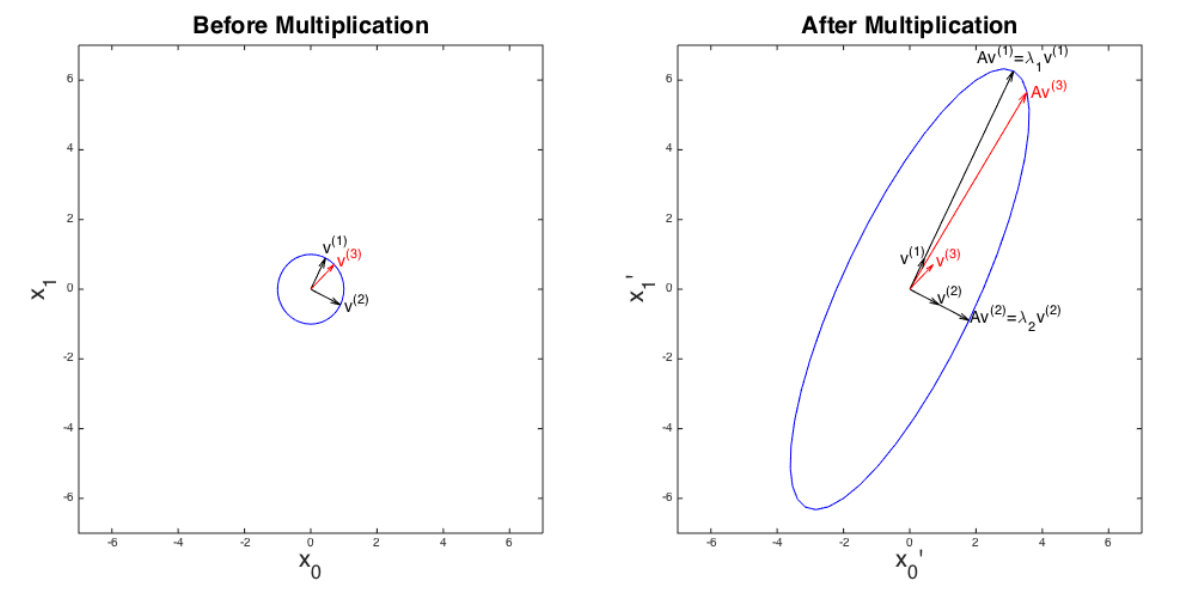
For an square matrix, there will always be eigenpairs (an eigenvalue and its corresponding eigenvector), although in some cases, some of the eigenvalues will be identical. And the eigenvector with the largest eigenvalue is called the principal eigenvector.
Computing Eigenvalues and Eigenvectors
There are various algorithms to compute eigenpairs of a matrix. Here we introduce two general methods.
Determinant
The determinant of a square matrix , denoted as or , is a function that maps matrices to real scalars. According to the rule that the determinant of a matrix must be 0 in order for to hold for a vector , we can develop a basic method to compute eigenpairs for the matrix .
We first restate the equation as . The eigenvector must be nonzero and thus the determinent of must be 0. The determinant of is an -th degree polynomial in , whose roots are eigenvectors of the matrix . For each eigenvalue , we can obtain a vector by solving the equation . Finally, we normalize to get the eigenvector corresponding to the eigenvalue . For example, consider the matrix:
Then is:
Considering the first row as the referenced row, we obtain the determinent equation:
By trial and error, we factor the equation into:
Solving the equation gives three eigenvalues , and . Then we use the eigenvalues to compute the corresponding eigenvectors:
Solving the three linear systems above and scale the vector we get three possible eigenvectors:
Finally, we normalize the three vectors into unit vectors:
The major drawback of solving the determinant polynomial is that it is extremely inefficient for large matrices. The determinant of an matrix has terms, implying time for computation. Fortunately, various algorithms have been proposed to compute the determinant more efficiently, such as the Decomposition methods.
Power Iteration
Compute the First Eigenpair
Power iteration is generally used to find the eigenvector with the largest (in absolute value) eigenvalue of a diagonalizable matrix . We start with any nonzero vector and then iterate:
We do the iteration until convergence, that is, is less than some small constant or we’ve reached the maximum iterations defined before. Let be the final vector we obtained. Then is approximately the eigenvector with greatest absolute eigenvalue of . Note that will be a unit vector and thus we can get the corresponding eigenvalue simply by computing , since .
Again, we set the maximum iterations = 100, x_0 = array([[1],[1],[1]]) and use the power iteration to compute the first eigenpair of the matrix defined in the last section:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
import numpy as np
A = np.array([[-2.,-2.,4.],[-2.,1.,2.],[4.,2.,5.]])
max_iter = 100
x_0 = np.array([[1.],[1.],[1.]])
x_f = None
for _ in range(max_iter):
x_f = np.dot(A, x_0) # x_f = Ax_0
x_f_norm = np.linalg.norm(x_f) # ||Ax_0||
x_f = x_f / x_f_norm # Ax_0 / ||Ax_0||
x_0 = x_f
tmp = np.dot(A, x_f)
x_f_T = x_f.reshape(1, -1)
lamda = np.dot(x_f_T, tmp)
print('First eigenvector of A:')
print(x_f)
print('First eigenvalue of A:', lamda[0][0])
1
2
3
4
5
First eigenvector of A:
[[0.36514837]
[0.18257419]
[0.91287093]]
First eigenvalue of A: 7.000000000000001
We see that power iteration yields the eigenpair that approximates the eigenpair with largest absolute eigenvalue obtained by solving the determinant polynomial. However, power iteration only computes the first eigenpair rather than all eigenpairs of a matrix. Fortunately, we can find all eigenpairs of a symmetric matrix by applying power iteration multiple times.
Find all Eigenpairs of Symmetric Matrix
For the symmetric matrix defined in the last section, we first compute the first eigenvector of the original matrix. And then we remove the first eigenvector from and obtain a modified matrix . The first eigenvector of the new matrix is the second eigenvector (eigenvector with the second-largest eigenvalue in absolute value) of the original matrix . We continue this process until we find the last eigenvector. In each step of the process, power iteration is used to find the first eigenpair of the new matrix.
In the first step, we use power iteration to compute the first eigenpair of the original matrix :
In the second step, we create a new matrix
and use power iteration on to compute its first eigenpair. The first eigenpair of is the second eigenpair of because:
-
If is the first eigenvector of with corresponding eigenvalue , it is also an eigenvector of with corresponding eigenvalue .
Note that since is a unit vector. In other words, we eliminate the influence of the first eigenvector by setting its associated eigenvalue to zero.
-
If and are an eigenpair of other than the first eigenpair , then they are also an eigenpair of :
Note that since the eigenvectors of a symmetric matrix are orthogonal.
In the third step, we use the power iteration to compute the first eigenpair of the matrix , which is also the second eigenpair of the original matrix :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
B = np.array([[-2.9331,-2.4667,1.6669],[-2.4667,0.7666,0.8331],[1.6669,0.8331,-0.8337]])
max_iter = 100
x_0 = np.array([[1.],[1.],[1.]])
x_f = None
for _ in range(max_iter):
x_f = np.dot(B, x_0) # x_f = Bx_0
x_f_norm = np.linalg.norm(x_f) # ||Bx_0||
x_f = x_f / x_f_norm # Bx_0 / ||Bx_0||
x_0 = x_f
tmp = np.dot(B, x_f)
x_f_T = x_f.reshape(1, -1)
lamda = np.dot(x_f_T, tmp)
print('First eigenvector of B:')
print(x_f)
print('First eigenvalue of B:', lamda[0][0])
1
2
3
4
5
First eigenvector of B:
[[ 0.81647753]
[ 0.40823876]
[-0.40829592]]
First eigenvalue of B: -5.0000166802782875
Next, we create a new matrix using the second eigenpair:
Again, we apply the power iteration on the new matrix and find the last eigenpair of :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
C = np.array([[0.4003,-0.8002,0.0000],[-0.8002,1.5997,-0.0002],[0.0000,-0.0002,-0.0002]])
max_iter = 100
x_0 = np.array([[1.],[1.],[1.]])
x_f = None
for _ in range(max_iter):
x_f = np.dot(C, x_0) # x_f = Cx_0
x_f_norm = np.linalg.norm(x_f) # ||Cx_0||
x_f = x_f / x_f_norm # Cx_0 / ||Cx_0||
x_0 = x_f
tmp = np.dot(C, x_f)
x_f_T = x_f.reshape(1, -1)
lamda = np.dot(x_f_T, tmp)
print('First eigenvector of C:')
print(x_f)
print('First eigenvalue of C:', lamda[0][0])
1
2
3
4
5
First eigenvector of C:
[[-4.47374583e-01]
[ 8.94346675e-01]
[-8.94266155e-05]]
First eigenvalue of C: 1.9999800807969734
We multiply the first eigenvector of by since we require that the first nonzero component of an eigenvector be positive:
Eigendecomposition
Given linearly independent eigenvectors of an matrix with corresponding eigenvalues , we can form the matrix of eigenvectors and diagonal matrix of eigenvalues:
The eigendecompisition of is then given by:
Not every matrix can be decomposed into eigenvalues and eigenvectors. Particularly, every real symmetric matrix can be decomposed into an expression using eigenvectors and eigenvalues:
where is an orthogonal matrix composed of eigenvectors of and thus . For example, the real symmetric matrix can be decomposed by:
The eigendecomposition of a matrix tells us many useful facts about the matrix:
-
The matrix is singular if and only if any of the eigenvalues are . Suppose that an eigenvalue of the matrix is and the corresponding eigenvector is , then we have:
This means the column vector is the linear combination of other column vectors, implying the matrix is singular. And if the matrix is singular, there must be an eigenvalue that is equal to .
-
A matrix whose eigenvalues are all positive is called positive definite; a matrix whose eigenvalues are all positive or zero valued is called positive semidefinite; the negative definite and the negative semidefinite is defined in a similar way.
Conclusion
In this blog, we introduce eigenvalues and eigenvectors of a square matrix, two general method to compute eigenpairs and the eigendecomposition of a matrix. Eigendecomposition is important for lots of useful algorithms, such as the Principal Component Analysis (PCA) and PageRank.