Introduction
Backpropagation, a fast algorithm to compute gradients, is essential to train deep neural networks and other deep models. In this blog, I’ll try to explain how it actually works in a simple computation graph and fully connected neural network.
Derivatives and Chain Rule
For the function , the derivative tells us how the changes of affect . For example, if , then we have , meaning that changing in a speed of leads to changing at a speed of . We have the sum rule and product rule for derivatives:
When it comes to composite function like , we use the chain rule to obtain the derivative:
Moving towards two dimension, the chain rule becomes so called “sum over paths” rule:
Under such situation, we can consider that there are two paths that relate to :
We just compute the derivatives on each path and sum them to obtain the final result. This is why we call it “sum over paths” rule. As for higher dimension, the chain rule becomes more general:
Derivatives on Simple Computational Graph
depicts a simple computational graph, where are input variables, are intermediary variables:
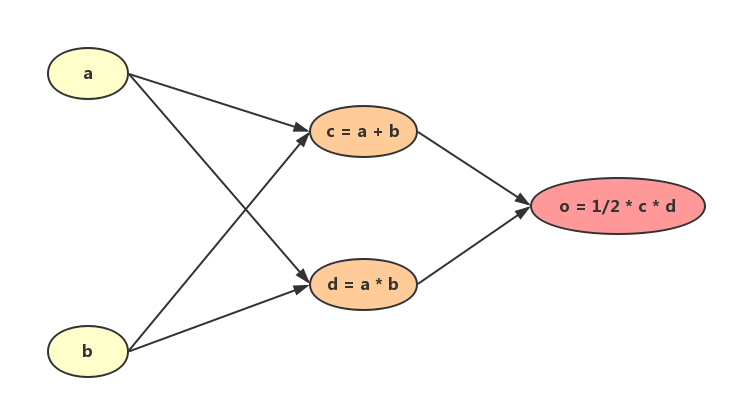
Our goal is to figure out how the changes of related variables affect the output, that is, to find out all the partial derivatives .
Let , we first move forward along the graph to compute the value of (the “feed-forward” process in neural network):
Next, we compute derivatives for each variable, using the “sum over paths” rule:
This is what we call “forward-mode differentiation”, in which we start from every variable and move forward to the output to compute the derivatives. Think about the computational paths we’ve gone through:
We’ve repeated computing and for three times! As the number of variables increasing, the number of redundant computations would grow exponentially. Therefore, we need to improve the derivatives computations using a method like dynamic programming.
Here comes the “reverse-mode differentiation”. Instead of starting from each variable, we can start from the output and move backward to compute every derivative. First, we obtain:
Next, we find that is the “parent” of and . Thus we get corresponding partial derivatives and stores them in memory:
Finally, we find that both and are “parents” of and . We directly use and stored in memory to compute derivatives of and :
This is what we call “backpropagation”. In fact, it’s just a dynamic programming algorithm to compute the derivatives fast.
Backpropagation in Fully Connected Neural Network
shows a simple fully connected neural network structure:
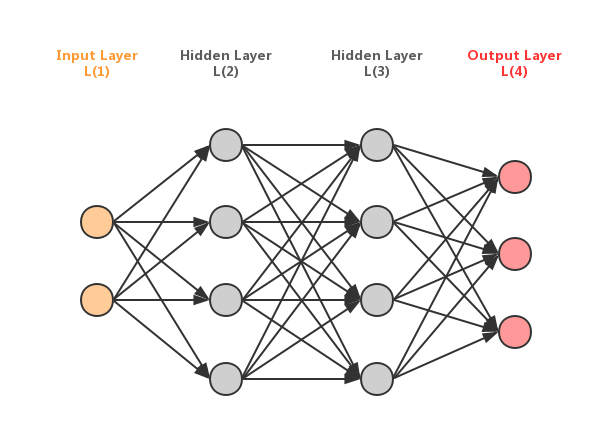
We define following symbols:
- Activation function:
- Number of neural layers:
- Value of neuron in layer before activated:
- Value of neuron in layer after activated:
- Weight for the connection from neuron in to neuron in layer:
- Bias for neuron in layer:
- Cost function: , where contains all the weights and biases that should be learned. There are two assumptions about from Nielsen’ book:
- The cost function can be written as an average , where denotes the cost of a single training example, .
- The cost function can be written as a function of the outputs from the neural network:
- Error of neuron in layer (i.e, error of ): . This “error” measures how the changes of affect the cost function, meaning that will change at a speed of when changes at a speed of . Hence, if a little change is added into to become , then will change into
Now suppose that we have a batch of training examples , which are fed into the network in to update all the weights and biases using SGD. Hence, our goal is to find out all the gradients and . First of all, for each training example with label , we run feed-forward to obtain its cost :
After running the feed-forward for all training examples in $X$, we finally get $J(\theta) = \frac{1}{n}\sum_{i=1}^n C_i$. Unfortunately, we can not directly use $J(\theta)$ to compute all the gradients since different $x^{(i)}$ has different $a^4$. Instead, we compute the sample gradients for each training example $x^{(i)}$:
And then average all the sample gradients to obtain final gradients:
Now we begin to compute the sample gradients for a single training example . Before calculation, we should remember following 4 equations (let denotes the number of layers in a network, and denotes the number of neurons in layer ):
In practice, we first compute , followed by applying on each layer to find out every , which is finally used to obtain our goals, and . Next, let’s begin our calculation:
Knowing formula of the activation function and the cost function , we can compute all the sample gradients we need. After averaging those sample gradients obtained through above 5 steps, we are able to find out every and in a batch training data, and use SGD method to update the weights and biases.
Conclusion
Backpropagation is the key algorithm to build all kinds of deep learning models. Knowing how it works in dense neural network is the fundamental premise of understanding its role in nowadays advanced deep models, such as RNN, LSTM and CNN. I’ll continue to explain how it works in those models in later blogs.